2023. 12. 29. 14:03ㆍ프로그래밍 공부/Data Structure
7.1 일반 트리
생산성 전문가들은 획기적인 전환점은 "비선형적으로" 생각하는 것이라고 말한다.
이 장에서 우리는 컴퓨팅에서 가장 중요한 비선형 자료 구조 중 하나인 트리에 대해 논의한다.
트리 구조는 실제로 데이터 조직에서 획기적인 전환점인데,
이는 리스트와 같은 선형 자료 구조를 사용할 때보다
훨씬 빠른 속도로 많은 알고리즘을 구현할 수 있게 해준다.
트리는 또한 데이터를 위한 자연스러운 조직을 제공하기 때문에
파일 시스템, 그래픽 사용자 인터페이스, 데이터베이스,
웹 사이트 및 기타 컴퓨터 시스템에서 어디에나 있는 구조가 되었다.
생산성 전문가들이 "비선형" 사고를 의미하는 것이 항상 명확하지는 않지만,
트리가 "비선형"이라고 말할 때,
연속적인 객체들 사이의 단순한 "전"과 "후"의 관계보다 더 풍부한 조직적 관계를 말한다.
트리의 관계는 계층적(hierarchical)이며,
어떤 객체는 "위"이고 어떤 객체는 "아래"이다.
실제로 트리 자료 구조의 주요 용어는 가족 트리에서 유래했으며,
"부모", "자식", "조상", "후손"은 관계를 설명하는 데 가장 일반적인 단어이다.
그림 7.1에서 가족 트리의 예를 보여준다.
그림 7.1: 창세기 25~36장에 기록된 아브라함의 후손들을 보여주는 가계도.

7.1.1 트리의 정의 및 특성
트리(tree): 요소를 계층적으로 저장하는 추상적인 데이터 타입
최상위 요소를 제외하고 트리의 각 요소에는
부모(parent) 요소와 0개 이상의 자식(children) 요소가 있다.
트리는 보통 요소를 타원이나 직사각형 안에 배치하고
부모와 자식 사이의 연결을 직선으로 그려서 시각화된다.
(그림 7.2 참조)
일반적으로 최상위 요소를 트리의 루트(root)라고 부르지만,
최상위 요소로 그려지고 다른 요소들은 아래에 연결된다
(식물 트리의 바로 반대).
그림 7.2: 가상 기업의 조직을 나타내는 17개의 노드가 있는 트리.
루트 - Electronics R'Us
루트의 자식 - R&D, Sales, Purchase, Manufacturing.
내부 노드 존재 - Sales, International, External, Electronics R'Us, Manufacturing
공식적인 트리 정의
트리(tree) T: 노드가 부모-자식 관계를 갖도록 하는 요소를 저장하는 노드 집합
이는 다음 속성을 만족한다:
• T가 비어 있지 않으면 T의 루트라고 하는 특수한 노드를 가진다.
루트(root): 부모를 가지지 않는 노드
• 루트와 다른 T의 각 노드 v는 고유한 부모(parent) 노드 w를 가진다.
부모 w를 가진 모든 노드는 w의 자식(child)이다.
트리는 정의에 따라 비어 있을 수 있으며, 이는 트리에 노드가 없음을 의미한다.
이 규칙을 통해 트리 T가 비어 있거나
T의 루트라고 하는 노드 r과 루트가 r의 자식인
(아마도 비어 있는) 트리 집합으로 구성되도록
트리를 재귀적으로 정의할 수도 있다.
기타 노드 관계
형제(sibling) 노드: 같은 부모의 자식인 두 노드
외부(external) 노드 = 자식이 없는 노드 v = 리프(leaf) 노드
내부(internal) 노드 = 자식이 하나 이상 있는 노드 v
예제 7.1: 대부분의 운영 체제에서
파일은 계층적으로 중첩된 디렉토리(폴더라고도 함)로 구성되며,
이 디렉토리는 트리의 형태로 사용자에게 표시된다. (그림 7.3 참조)
좀 더 구체적으로
트리의 내부 노드는 디렉토리와 연결되고
외부 노드는 일반 파일과 연결된다.
UNIX와 리눅스 운영 체제에서
트리의 루트는 적절하게 "루트 디렉토리"라고 불리며,
기호 "/"로 표시된다
그림 7.3: 파일 시스템의 일부분을 나타내는 트리.

만약 u = v이거나 u가 v의 부모의 조상(ancestor)이라면, 노드 u는 노드 v의 조상이다.
반대로, 만약 u가 v의 조상이라면, 노드 v는 노드 u의 후손(descendent)이라고 말한다.
예를 들어, 그림 7.3에서 cs252/는 papers/의 조상이고, pr3는 cs016/의 후손이다.
노드 v에 루트가 정의된(rooted) T의 부분 트리(subtree)는
T에서 v의 모든 후손으로 구성된 트리이다(v 자체를 포함함).
그림 7.3에서 cs016/에 루트를 둔 부분 트리는
노드 cs016/, grades, homeworks/, programs/, hw1, hw2, hw3, pr1, pr2, pr3으로 구성된다.
트리의 간선 및 경로
트리 T의 간선(edge): u가 v의 부모가 되는 노드 쌍 (u, v). 그 반대의 경우도 마찬가지이다.
트리 T의 경로(path): 연속적인 두 노드가 간선을 형성하는 노드의 시퀀스
예를 들어, 그림 7.3의 트리는 경로 (cs252/, projects/, demos/, market)를 포함한다.
예제 7.2: Java 프로그램의 클래스 간 상속 관계는 트리를 형성한다.
루트 java.lang.Object = 모든 클래스의 상위 클래스
각 클래스 C = 루트의 후손 = C를 확장하는 클래스의 하위 트리의 루트
상속 트리 - C에서 루트 java.lang.Object로 가는 경로가 있다.
순서 트리
각 노드의 자식에 대해 정의된 선형 순서가 있으면 트리를 순서화(ordered)한다.
즉, 노드의 자식을 첫 번째, 두 번째, 세 번째 등으로 식별할 수 있다.
이러한 순서화는 대개 형제 노드를
순서에 따라 왼쪽에서 오른쪽으로 배열함으로써 시각화된다.
순서 트리(ordered tree):
일반적으로 형제 노드 간의 선형 순서를 올바른 순서로 나열하여 나타낸다.
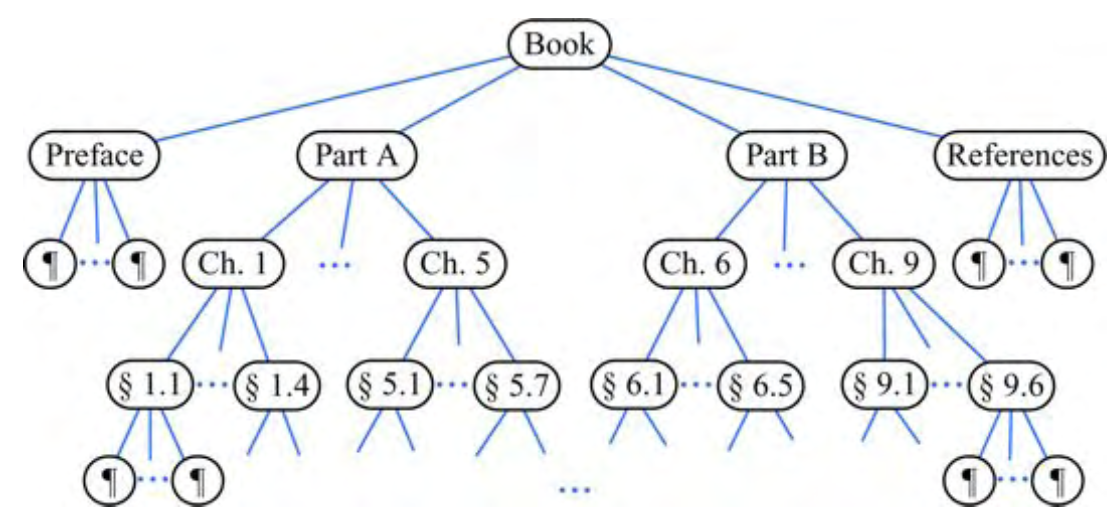
예 7.3: 책과 같이 구조화된 문서의 구성 요소는
내부 노드가 부분, 장, 섹션이고
외부 노드가 단락, 표, 그림 등인 트리로 계층적으로 구성된다.
(그림 7.4 참조) 트리의 루트는 책 자체에 해당된다.
실제로 트리를 더 확장하여
문장으로 구성된 단락,
단어로 구성된 문장,
문자로 구성된 단어를 보여주는 것을 고려해 볼 수 있다.
이러한 트리는 순서 트리의 한 예인데,
각 노드의 자식들 사이에 잘 정의된 순서가 있기 때문이다.
그림 7.4: 책과 관련된 순서 트리
7.1.2 트리 추상 데이터 타입
트리 ADT는 요소들을 위치에 저장하는데,
이것은 리스트의 위치들과 마찬가지로 이웃한 위치들과 관련하여 정의된다.
트리의 위치(position) = 트리의 노드(node)
이웃한 위치 = 유효한 트리를 정의하는 부모 자식 관계
따라서 트리에 대해 "위치"와 "노드"라는 용어를 서로 교환하여 사용한다.
리스트 위치와 마찬가지로 트리에 대한 위치 객체는 다음 메소드를 지원한다:
element(): 이 위치에 저장된 객체를 반환한다.
그러나 트리에서 노드 위치의 실질적인 힘은
다음과 같은 위치를 반환하고 수용하는
트리 ADT의 접근자 메소드(accessor method)에서 나온다:
root():
트리의 루트를 반환한다. 트리가 비어 있으면 오류가 발생한다.
parent(v):
v의 부모를 반환한다. v가 루트인 경우 오류가 발생한다.
children(v):
노드 v의 자식이 포함된 반복 가능한 컬렉션을 반환한다.
트리 T가 순서대로 정렬되면
반복 가능한 컬렉션인 children(v)은 v의 자식을 순서대로 저장한다.
v가 외부 노드이면 children(v)은 비어 있다.
위의 기본 접근자 메소드 외에도
다음과 같은 쿼리 메소드(query method)도 포함하고 있다:
isInternal(v):
노드 v가 내부에 있는지 테스트한다.
isExternal(v):
노드 v가 외부에 있는지 테스트한다.
isRoot(v):
노드 v가 루트인지 여부를 테스트한다.
이러한 방법은 트리를 사용한 프로그래밍을 더 쉽고 가독성 있게 만든다.
왜냐하면 우리는 직관적이지 않은 조건을 사용하는 대신
if문과 while문의 조건에서 사용할 수 있기 때문이다.
트리 구조와 반드시 관련되지 않은 일반적인 메소드(generic method)도 많이 있다.
다음을 포함하여 트리가 지원해야 할 것이다:
size():
트리의 노드 수를 반환한다.
isEmpty():
트리에 노드가 있는지 여부를 테스트한다.
iterator():
트리의 노드에 저장된 모든 요소의 반복자를 반환한다.
positions():
트리의 모든 노드의 반복 가능한 컬렉션을 반환한다.
replace(v,e):
e로 대체하고 노드 v에 저장된 요소를 반환한다.
어떤 입장을 인수로 삼는 어떤 메소드이든 그 입장이 유효하지 않다면
오류 조건을 생성해야 한다.
여기서는 트리에 대한 전문화된 업데이트 메소드를 정의하지 않는다.
대신, 다음 장에서 트리의 특정 응용 프로그램과 함께
다른 트리 업데이트 메소드를 설명하는 것을 선호한다.
7.1.3 트리의 구현
코드 조각 7.1에 표시된 Java 인터페이스는 트리 ADT를 나타낸다.
오류 조건은 다음과 같이 처리된다.
인수로 위치를 취할 수 있는 각 메소드는
잘못된 위치임을 나타내기 위해 InvalidPositionException을 던질 수 있다.
메소드 부모는 루트에서 호출되는 경우 BoundaryViolationException을 던진다.
메소드 루트는 빈 트리에서 호출되는 경우 EmptyTreeException을 던진다.
코드 조각 7.1 : 트리 ADT를 나타내는 자바 인터페이스 트리.
응용 프로그램에 따라 추가 업데이트 메소드가 추가될 수 있다.
그러나 이러한 메소드는 인터페이스에 포함하지 않는다.
/**
* An interface for a tree where nodes can have an arbitrary number of childern.
*/
public interface Tree<E> {
/** Returns the number of nodes in the tree. */
public int size();
/** Returns whether the tree is empty. */
public boolean isEmpty();
/** Returns an iterator of the elements stored in the tree. */
public Iterator<E> iterator();
/** Returns an iterable collection of the nodes. */
public Iterable<Position<E>> positions();
/** Replaces the element stored at a given node */
public E replace(Position<E> v, E e)
throws InvalidPositionException;
/** Returns the root of the tree. */
public Position<E> root() throws EmptyTreeException;
/** Returns the parent of the tree. */
public Position<E> parent(Position<E> v)
throws InvalidPositionException, BoundaryViolationException;
/** Returns an iterable collection of the children of a given node. */
public Iterable<Position<E>> children(Position<E> v)
throws InvalidPositionException;
/** Returns whether a given node is internal. */
public boolean isInternal(Position<E> v)
throws InvalidPositionException;
/** Returns whether a given node is external. */
public boolean isExternal(Position<E> v)
throws InvalidPositionException;
/** Returns whether a given node is the root of the tree. */
public boolean isRoot(Position<E> v)
throws InvalidPositionException;
}일반 트리의 연결 구조
트리 T를 실현하는 자연스러운 방법은 연결 구조(linked structure)를 사용하는 것인데,
여기서 T의 각 노드 v를 다음 필드를 가진 위치 객체(그림 7.5a 참조)로 표시한다:
- v에 저장된 요소에 대한 참조
- v의 부모에 대한 링크
- v의 자식에 대한 링크를 저장하는 일종의 컬렉션(예를 들어, 리스트 또는 배열)
v가 T의 루트이면 v의 상위 필드는 null이다.
또한 내부 변수에 T의 루트와 T의 노드 수에 대한 참조를 저장한다.
이 구조는 그림 7.5b에 개략적으로 나타나 있다.
그림 7.5: 일반 트리의 연결 구조:
(a) 노드와 관련된 위치 객체;
(b) 노드와 그 자식 노드와 관련된 자료 구조의 부분.

표 7.1은 연결 구조를 이용한 일반 트리 구현의 성능을 요약한 것이다.
각 노드 v의 자식을 저장하기 위해 컬렉션을 사용함으로써
이 컬렉션에 대한 참조를 반환하는 것만으로 자식(v)을 구현할 수 있다.
표 7.1:
연결 구조로 구현된 n개의 노드 일반 트리의 메소드의 실행 시간.
cv를 노드 v의 자식 수라고 한다.
공간 사용량은 O(n)이다.
| 연산 | 시간 |
| size, isEmpty | O(1) |
| iterator, positions | O(n) |
| replace | O(1) |
| root, parent | O(1) |
| children(v) | O(Cv) |
| isInternal, isExternal, isRoot | O(1) |
7.2 트리 순회 알고리즘
이 절에서는 트리 ADT 메소드를 통해 트리에 접근하여
순회 계산을 수행하는 알고리즘을 제시한다.
7.2.1 깊이 및 높이
v를 트리 T의 노드라고 하자.
v의 깊이(depth): v 자체를 제외한 v의 조상의 수
예시) 그림 7.2의 트리에서 International을 저장하는 노드는 깊이 2를 갖는다.
이 정의는 T의 루트의 깊이가 0임을 의미한다.
노드 v의 깊이는 다음과 같이 재귀적으로 정의할 수도 있다:
• v가 루트라면 v의 깊이는 0이다
• 그렇지 않으면 v의 깊이는 v의 부모의 깊이에 1을 더한 값이다.
이러한 정의를 바탕으로 T에 있는 노드 v의 깊이를 계산하기 위한
간단한 재귀적 알고리즘인 깊이를 코드 조각 7.2에서 제시한다.
이 방법은 v의 상위에서 재귀적으로 호출하고 반환된 값에 1을 더한다.
이 알고리즘의 간단한 자바 구현은 코드 조각 7.3에 나와 있다.
코드 조각 7.2: 트리 T에서 노드 v의 깊이를 계산하기 위한 알고리즘.
Algorithm depth(T, v):
if v is the root of T then
return 0
else
return 1 + depth(T, w), where w is the parent of v in T
코드 조각 7.3: 자바로 작성된 메소드 depth.
public static <E> int depth(Tree<E> T, Position<E> v) {
if (T.isRoot(v))
return 0;
else
return 1 + depth(T, T.parent(v));
}
알고리즘이 v의 각 조상에 대해 일정한 시간 재귀적 단계를 수행하기 때문에
알고리즘 depth(T, v)의 실행 시간은 O(dv)이며,
여기서 dv는 트리 T에서 노드 v의 깊이를 나타낸다.
따라서, 알고리즘 depth(T, v)는
최악의 경우 T의 노드가 깊이 n - 1을 가질 수 있으므로
O(n) 최악의 경우 시간에서 실행된다.
이러한 실행 시간은 입력 크기의 함수이지만,
매개변수 dv는 n보다 훨씬 작을 수 있으므로
실행 시간을 이 매개변수 dv의 관점에서 특성화하는 것이 더 정확하다.
높이
트리 T의 노드 v의 높이(height)도 재귀적으로 정의된다:
• v가 외부 노드인 경우 v의 높이는 0이다
• 그렇지 않으면 v의 높이는 v의 자식의 최대 높이에 1을 더한 값이다.
비어 있지 않은 트리 T의 높이는 T의 루트의 높이이다.
예를 들어, 그림 7.2의 트리는 높이가 4이다.
또한, 높이는 다음과 같이 볼 수도 있다.
제안 7.4: 비어 있지 않은 트리 T의 높이는 T의 외부 노드의 최대 깊이와 같다.
저희는 위의 명제를 기반으로 비어 있지 않은 트리 T의 높이와
코드 조각 7.2의 알고리즘 깊이를 계산하기 위해
코드 조각 7.4에 나와 있고
코드 조각 7.5의 자바로 구현된
height1이라는 알고리즘을 여기에 제시한다.
코드 조각 7.4:
비어 있지 않은 트리의 높이를 계산하기 위한 알고리즘 height1.
이 알고리즘은 알고리즘 depth(코드 조각 7.2)를 호출한다.
Algorithm height1(T):
h ← 0
for each vertex v in T do
if v is the root of T then
h ← max(h, depth(T, v))
return h
코드 조각 7.5: 자바로 작성된 메소드 height1.
class java.lang.Math의 max 메소드 사용에 주목하자.
public static <E> int height1(Tree<E> T) {
int h = 0;
for (Position<E> v : T.positions()) {
if (T.isExternal(v))
h = Math.max(h, depth(T, v));
}
return h;
}
안타깝게도 알고리즘 height1은 그다지 효율적이지 않다.
height1은 T의 각 외부 노드 v에서 알고리즘 depth(v)를 호출하므로
height1의 실행 시간은 O(n + Σv(1 + dv))로 주어진다.
(n: T의 노드 수 ,dv: 노드 v의 깊이, E: T의 외부 노드 집합)
최악의 경우 합 Σv(1 + dv)는 n^2에 비례한다.
따라서 알고리즘 height1은 O(n^2) 시간에 실행된다.
코드 조각 7.6에 나타나 있고
코드 조각 7.7의 자바로 구현된 알고리즘 height2는
높이의 재귀적 정의를 사용하여
트리 T의 높이를 보다 효율적으로 계산한다.
코드 조각 7.6:
노드 v에 루트를 둔 트리 T의 서브트리의 높이를 계산하기 위한 알고리즘 height2.
Algorithm height2(T,v):
if v is an external node in T then
return 0
else
h ← 0
for each child w of v in T do
h ← max(h, height2(T, w))
return 1 + h
코드 조각 7.7:
자바로 작성된 메소드 height2.
public static <E> int depth(Tree<E> T, Position<E> v) {
if (T.isExternal(v)) return 0;
int h = 0;
for (Position<E> w : T.childern(v))
h = Math.max(h, height2(T, w));
return 1 + h;
}
알고리즘 height2가 height1보다 더 효율적이다.
알고리즘은 재귀적이고,
만약 처음에 T의 루트에서 호출된다면,
결국 T의 각 노드에서 호출될 것이다.
따라서, 우리는 (재귀적이지 않은 부분에서)
각 노드에서 소요된 시간을 모든 노드에 걸쳐 합함으로써
이 방법의 실행 시간을 결정할 수 있다.
children(v)에서 각 노드를 처리하는 데 O(cv) 시간이 걸리고,
(cv: 노드 v의 자식 노드 수)
또한, 루프가 cv번 반복되고
루프의 각 반복에 O(1) 시간과 v의 자식 노드에 대한 재귀적 호출 시간을 더한다.
따라서 알고리즘 height2는 각 노드 v에서 O(1 + cv) 시간을 소비하고,
그것의 실행 시간은 O(Σv(1 + cv))이다.
분석을 완료하기 위해 다음과 같은 성질을 이용한다.
명제 7.5: T를 n개의 노드를 가진 트리라고 하고,
cv를 T의 노드 v의 자식의 수라고 한다.
그런 다음 T의 정점에 대한 합계, Σv cv= n-1.
정당화: 루트를 제외한 T의 각 노드는 다른 노드의 자식이므로
위의 합에 한 단위를 기여한다.
제안 7.5에 의해 알고리즘 height2의 실행 시간은
T의 루트에서 호출될 때 O(n)이며, 여기서 n은 T의 노드 수이다.
7.2.2 전위 순회
트리 T의 순회(traversal): T의 모든 노드에 접근하는 체계적인 방법
이 절에서는 트리에 대한 기본적인 순회 계획을 전위 순회(preorder traversal)라고 부른다.
다음 절에서는 후위 순회(postorder traversal)라고 불리는 또 다른 기본적인 순회 계획을 공부할 것이다.
트리 T의 전위 순회(preorder traversal):
트리 T의 루트를 먼저 찾고 그 트리의 자식에 루트를 둔 부분 트리들을 재귀적으로 순회한다.
트리의 순서가 정해지면 하위 트리들은 자식의 순서에 따라 순회한다.
노드 v의 "방문"과 관련된 특정 동작은 순회의 적용에 따라 다르며,
카운터를 증가시키는 것부터 v에 대한 어떤 복잡한 계산을 수행하는 것까지 포함할 수 있다.
코드 조각 7.8 - 노드 v에 루트를 둔 부분 트리의 전위 순회에 대한 의사 코드
초기에는 이 알고리즘을 preorder(T,T.root())이라고 부른다.
코드 조각 7.8: 노드 v에 루트를 둔
트리 T의 서브트리의 전위 순회를 수행하기 위한 알고리즘 preorder.
Algorithm preorder(T,v):
perform the "visit" action for node v
for each child w of v in T do
preorder(T, v) {recursively traverse the subtree rooted at w}
전위 순회 알고리즘은
순서에서 부모가 항상 자식보다 먼저 와야 하는 트리의 마디들을
선형적으로 순서화하는 데 유용한다.
그러한 순서화들은 여러 가지 다른 응용 프로그램을 가지고 있다.
다음 예제에서 그러한 응용 프로그램의 간단한 예를 살펴본다.
그림 7.6:
각 노드의 자식이
왼쪽에서 오른쪽으로 순서가 지정된 순서대로
정렬된 트리의 순회를 미리 정렬한다.
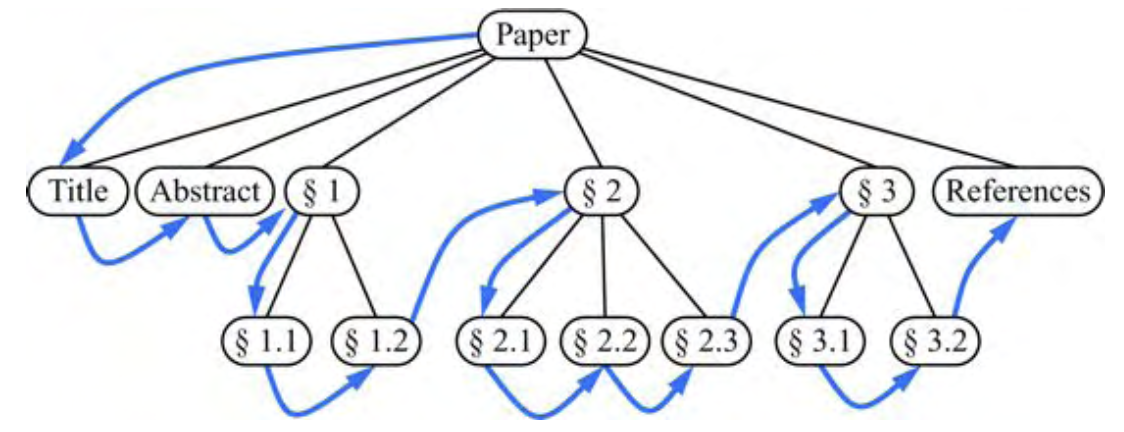
예제 7.6:
예제 7.3과 같이 문서와 관련된 트리의 전위 순회는
문서 전체를 처음부터 끝까지 순차적으로 검사한다.
순회 전에 외부 노드를 제거하면
순회는 문서의 목차를 검사한다(그림 7.6 참조)
전위 순회는 트리의 모든 노드에 접근하는 효율적인 방법이기도 하다.
이를 정당화하기 위해 노드를 방문하는 데 O(1) 시간이 걸린다는 가정 하에
n개의 노드가 있는 트리 T의 전위 순회의 실행 시간을 고려해 보겠다.
전위 순회 알고리즘의 분석은
실제로 7.2.1절에 주어진 알고리즘 height2(코드 조각 7.7)의 분석과 비슷하다.
각 노드 v에서 전위 순회 알고리즘의 비재귀적 부분은
시간 O(1 + cv)를 필요로 하며,
(cv: v의 자식)
따라서 명제 7.5에 의해 T의 전위 순회의 전체 실행 시간은 O(n)이다.
코드 조각 7.9의 자바로 구현된 알고리즘 toStringPreorder(T, v)는
T의 노드 v의 서브트리에 대한 전위 인쇄를 수행한다.
즉, v에 루트가 있는 서브트리의 전위 순회를 수행하고
노드가 방문할 때 노드에 저장된 요소를 인쇄한다.
순서 트리 T에 대해 메소드 T.children(v)은
v의 자식에 순서대로 접근하는 반복 가능한 컬렉션을 반환한다.
코드 조각 7.9:
T의 노드 v의 서브트리에 있는 요소들의
전위 인쇄를 수행하는 메소드 to StringPreorder(T, v).
public static <E> int depth(Tree<E> T, Position<E> v) {
String s = v.element().toString(); // the main "visit" action
for (Position<E> w : T.childern(v))
s += ", " + toStringPreorder(T, w);
return s;
}
트리 전체의 문자열 표현을 생성하는 전순서 순회 알고리즘의 흥미로운 응용이 있다.
트리 T에 저장된 각 원소 e에 대하여 e.toString()을 호출하면
e와 연관된 문자열이 반환된다고 다시 가정하자.
트리 T의 부모 문자열 표현 P(T)는 다음과 같이 재귀적으로 정의된다.
만약 T가 하나의 노드 v로 이루어진다면, T는 다음과 같다
P(T) = v.element().toString().
그렇지않으면,
P(T) = v.element().toString()+"("+ P(T1) + "," +··+", "+ P(Tk) +")",
여기서 v는 T의 근이고 T1, T2,..., Tk는 T가 순서 트리일 때
순서대로 주어진 v의 자식에 루트를 둔 부분 트리이다.
위의 P(T)의 정의는 재귀적이다.
또한, 우리는 끈 연결을 나타내기 위해 여기서 "+"를 사용하고 있다.
그림 7.2의 트리를 괄호로 나타내면 그림 7.7과 같다.
그림 7.7: 그림 7.2의 트리에 대한 괄호 표시.
명확성을 위해 들여쓰기, 줄 바꿈 및 공백이 추가되었다.

위 알고리즘은 엄밀히 말하면 노드의 자식에서
재귀적 호출 사이에 발생하는 계산과 그 이후에 발생하는 계산이 있다.
하지만 재귀적 호출 이전에
노드의 내용물을 인쇄하는 주요 작업이 발생하기 때문에
우리는 여전히 이 알고리즘을 전위 순회로 간주한다.
코드 조각 7.10에 표시된
Java 메소드 parentheticRepresentation은
toStringPreorder(코드 조각 7.9)에 대한 메소드의 변형이다.
위에 주어진 정의를 구현하여 트리 T의 괄호와 관련된 문자열 표현을 출력한다.
메소드 parentheticRepresentation은 toStringPreorder와 마찬가지로
모든 Java 객체에 대해 정의된 toString 메소드를 사용한다.
실제로 이 메소드는 트리 객체에 대한 일종의 toString() 메소드로 볼 수 있다.
코드 조각 7.10: 알고리즘 부모 표현. + 연산자를 사용하여 두 문자열을 연결한다.
public static <E> int String parentheticRepresentation(Tree<E> T, Position<E> v) {
String s = v.element().toString(); // main visit action
if (T.isInternal(v)) {
Boolean firstTime = true;
for (Position<E> w : T.childern(v))
if (firstTime) {
s += " ( " + parentheticRepresentation(T, w); // the first child
firstTime = false;
}
else s += ", " + parentheticRepresentation(T, w); // subsequent child
s += " )"; // close parenthesis
}
return s;
}
연습 R-7.9의 코드 조각 7.10에 대한 수정을 검토하여
그림 7.7에 제시된 것과 더 유사한 방식으로 트리를 표시한다.
7.2.3 후위 순회
또 다른 중요한 트리 순회 알고리즘은 후위 순회(postorder traversal)이다.
이 알고리즘은 루트의 자식에 있는 부분 트리들을
먼저 재귀적으로 순회한 다음 루트를 방문하기 때문에
전위 순회의 반대로 볼 수 있다.
그러나 노드 v의 방문과 관련된 동작을 특화시켜
특정 문제를 해결하는 데 사용한다는 점에서 전위 순회와 유사하다.
여전히 전위 순회와 마찬가지로 트리가 순서가 정해지면
지정된 순서에 따라 노드 v의 자식들을 재귀적으로 호출한다.
후위 순회에 대한 의사 코드는 코드 조각 7.11에 나와 있다.
코드 조각 7.11: 노드 v에 루트를 둔
트리 T의 하위 트리의 후위 순회를 수행하기 위한 알고리즘 postorder.
Algorithm postorder(T,v):
for each child w of v in T do
postorder(T, v) {recursively traverse the subtree rooted at w}
perform the "visit" action for node v
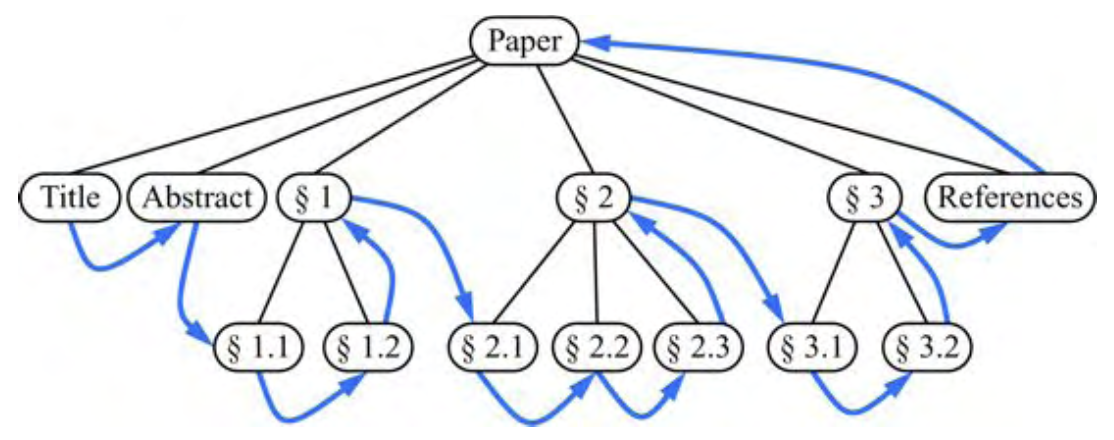
후위 순회의 이름은 이 순회 방법이
v에 루트를 둔 서브트리의 다른 모든 노드를 방문한 후
노드 v를 방문한다는 사실에서 유래한다(그림 7.8 참조)
그림 7.8: 그림 7.6의 주문 트리의 후위 순회.
후위 순회의 실행 시간 분석은 전위 순회의 실행 시간 분석과 유사하다.
(7.2.2절 참조) 알고리즘의 비재귀적 부분에 소요된 총 시간은
트리의 각 노드의 자식을 방문하는 데 소요된 시간에 비례하다.
따라서 n개의 노드가 있는 트리 T의 후위 순회는
각 노드를 방문하는 데 O(1) 시간이 걸린다고 가정하면 O(n) 시간이 걸린다.
즉, 후위 순회는 선형 시간으로 실행된다.
후위 순회의 예로,
저희는 코드 조각 7.12에서
트리 T의 후위 순회를 수행하는 StringPostorder에 대한 Java 메소드를 보여준다.
이 메소드는 노드에 저장된 요소를 방문할 때 인쇄한다.
코드 조각 7.12:
T의 노드 v의 서브트리에 있는 요소들의 후순위 인쇄를 수행하는
메소드 toStringPostorder(T, v)
이 메소드는 요소가 문자열 연결 연산에 관여할 때
암묵적으로 toString을 호출한다.
public static <E> String toStringPostorder(Tree<E> T, Position<E> v) {
String s = "";
for (Position<E> w : T.childern(v))
s += toStringPostorder(T, w) + " ";
s += v.element(); // main visit action
return s;
}
후위 순회법은
트리의 각 노드 v에 대한 일부 속성을 계산하려고 하지만
v에 대한 속성을 계산하려면
v의 자식에 대해 동일한 속성을 계산해야 하는 문제를 해결하는 데 유용하다.
이러한 응용은 다음 예제에 나와 있다.
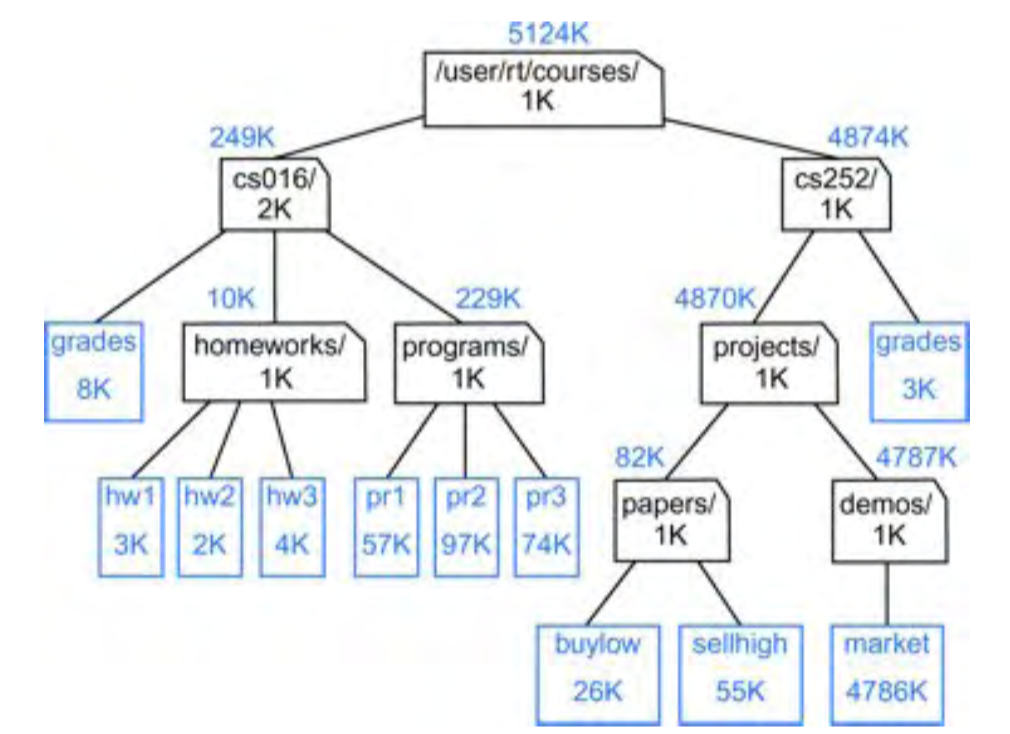
예제 7.7: 파일 시스템 트리 T를 생각해 보자.
외부 노드는 파일을 나타내고 내부 노드는 디렉터리를 나타낸다.
디렉터리에서 사용하는 디스크 공간을 계산하려고 하는데,
다음의 합으로 재귀적으로 주어진다고 가정하자:
• 디렉토리 자체의 크기
• 디렉토리의 파일 크기
• 자식 디렉토리가 사용하는 공간.
(그림 7.9 참조) 이 계산은 트리 T의 후위 순회로 수행할 수 있다.
내부 노드 v의 부분 트리가 순회한 후
v의 각 내부 자식이 사용하는 공간에 디렉토리 v 자체와
v에 포함된 파일의 크기를 더하여
v가 사용하는 공간을 계산하는데,
이 공간은 v의 자식의 재귀적 후위 순회로 계산된다.
디스크 공간 계산을 위한 재귀적 자바 메소드
예제 7.7에서 동기를 부여받은
코드 조각 7.13의 Java 메소드 diskSpace는
파일 시스템 트리 T의 후순 순회를 수행하여
T의 각 내부 노드와 연결된 디렉터리에서 사용하는 이름과 디스크 공간을 인쇄한다.
트리 T의 루트에서 호출하면
보조 메소드 이름과 크기가 O(1) 시간이 걸리는 경우
diskSpace는 O(n) 시간에 실행된다.
그림 7.9: 파일 시스템을 나타내는 그림 7.3의 트리로,
각 노드 내부의 관련 파일/디렉토리의 이름과 크기,
각 내부 노드 위의 관련 디렉토리가 사용하는 디스크 공간을 보여준다.
코드 조각 7.13: 메소드 diskSpace는
파일 시스템 트리의 각 내부 노드와 연결된 디렉토리에서
사용하는 이름과 디스크 공간을 인쇄한다.
이 메소드는 노드와 연결된 파일/디렉토리의 이름과 크기를 반환하기 위해
정의되어야 하는 보조 메소드 이름과 크기를 호출한다.
public static <E> int diskSpace(Tree<E> T, Position<E> v) {
int s = size(v); // start with the size of the node itself
for (Position<E> w : T.childern(v))
// add the recursively computed space used by the children of v
s += diskSpace(T, w);
if (T.isInternal(v)) {
// print name and disk space used
System.out.print(name(v) + ": " + s);
}
return s;
}
기타 종류의 순회
전위와 후위 순회가 트리의 마디를 방문하는 일반적인 방법이지만,
다른 순회도 생각해 볼 수 있다.
예를 들어, 우리는 d+1 깊이의 마디를 방문하기 전에
d 깊이의 모든 마디를 방문할 수 있도록 트리를 횡단할 수 있다.
이 순회에서 트리 T의 마디를 방문할 때 연속적으로 번호를 매기는 것을
T의 마디의 레벨 넘버링(level numbering)이라고 한다(7.3.5절 참조).
'프로그래밍 공부 > Data Structure' 카테고리의 다른 글
| 8장 우선순위 큐 (4) | 2023.12.31 |
|---|---|
| 7장 트리(2) (1) | 2023.12.30 |
| 6장 리스트와 반복자 (1) | 2023.12.22 |
| 5장 스택과 큐 (1) | 2023.12.20 |
| 4장 분석 도구 (1) | 2023.12.19 |